RabbitMQ Chat Post Mortem
NOTE 1: I’m preparing a post update to clarify some questions that I’m getting here and on Reddit. Also I’m creating some test scripts to try to easily reproduce the messaging bits so other people can test this scenario. So far I’m failing to kill RabbitMQ on my machine with 1000 consumers, 1 queue and 1 channel per consumer. I’ve got a loop publishing 50 bytes messages. I hope to publish this later in the afternoon.
NOTE 2: Since this blog is just a git repository on Github, you can track the changes transparently here:
Background
Last week I started preparing a chapter for the book I’m writing so I had to come up with an example on how to extend RabbitMQ. I was looking for something fairly simple to implement that at the same time proved of value for the reader. Since recently some custom exchanges had appeared on the mailing list, I thought that creating a custom exchange could be a nice example to implement, so I went for it.
In case you don’t know what RabbitMQ is, I’ll explain it briefly here. RabbitMQ is a messaging server that as such you use it to pass messages around in your applications. You can send event notifications through it; enqueue tasks for background processing; collect logs from many sources and filter them; and so on. Taking all that into account, creating a Chat where RabbitMQ is used as the message router doesn’t sound so crazy.
For that purpose I created the Recent History Exchange. The purpose of having such custom exchange was to provide the user that joined the chat room with a minimal context of the last 20 messages that passed through the chat room.
So I sat down and started hacking, in about 4 hours I’ve got the Chat Repository ready and up on Github. It was very very basic. The frontend part was based on YakRiak, a web chat with a Riak backend.
The Architecture
OK, let’s assume there’s an architecture as such behind this little book example.
First as some one said, I was cheating, I wrote all this in Erlang.
The HTTP bits of the chat: the HTML page, the CSS and Javascript was all served by Misultin, an Erlang web server. Also I used Misultin as a Websockets server to send the messages to the connected clients.
What happened when a user connects to the chat is this:
1) The server starts a Websockets connection to the user browser.
2) The Websockets loop starts a RabbitMQ consumer. This consumer takes care of creating a private auto delete queue on the server. This means each user has its own queue on the server. By making the queues auto delete, I’ve made sure that if the users closed his chat window, then his queue will be automatically deleted by RabbitMQ.
3) All queues where bound to the custom Recent History Exchange. As I said before, every user that connected to the chat got the last 20 messages thanks to this exchange. This exchange acted like a single chat room where every user was logged in.
4) Every time a user sent a message to the server, that message got fanout’ed to every queue bound to the exchange. Depending on the amount of queues created on the server, this pattern of message distribution can get very very slow. When the chat got 500~ users online and 10~ messages published per second, that meant the server was routing each of those ten messages to each of the 500~ queues.
5) Once the broker delivered the message to the private queue, the consumer took care of sending it back to the Websocket process that started it, and from there it was sent to the browser. The messages where transient, kept in memory by the broker while they were getting delivered to the consumers.
And that was basically it.
Some people raised valid complains about the chat interface having some CSS problems. Also I was too lazy to implement a rooster kind of feature. The goal of the chat was to test the proof of concept that was the Recent History Exchange. Just that, nothing more. It wasn’t meant to become a full blown chat. Perhaps in the future I could try to build a more interesting chat, but not in this case.
Also keep in mind that this was not made to compete with other solutions like the APE server or Node JS.
The Setup
To deploy the server I’ve got a vps200 from Servergrove: 1 GB of RAM and 2 cores. I asked for a bare bones installation of Ubuntu 10.04 on it. The account set up was really easy and their admin panel is pretty slick.
Once I’ve got the login details I ssh’ed into the server and compiled Erlang from source. From there it was a matter of 20 seconds to get RabbitMQ up and running. I used the latest Generic Unix Distribution to get it installed.
After I’ve got the server installed, I’ve added the Recent History Exchange and the Management Plugin. The latter so I could easily monitor the status of the server directly from the web.
Deployment Method
To deploy the code I used Github to get the source code for the application. Whenever there was a bug, or a new feature I wanted to add, like logging, what I did was to develop in my machine, pushed to Github, pulled on the server, compiled and restarted the Chat.
Going Live
To get the Chat up and running I didn’t do anything special. Erlang compiled with default options. RabbitMQ started with default options. Nothing fancy. There was no clustering set up or any kind of failover. As you see, this was a pretty minimalistic setup. No load balancers, no heartbeats to check system health, etc.
Once I’ve got the chat up and running. I’ve showed it to some friends on Twitter to be sure it wasn’t broken. The next day I decided to ask Reddit to try to take down the chat. There the fun started.
Then Reddit users started to do some nasty things against the poor ol’ little server. Some guy ran Apache Benchmark against it. Here are the results: 100000 requests in 43~ seconds. I would say that’s not bad for such a simple and smallish setup.
Not happy with that another developer –@danopia– created some Ruby gists to act as bots that were constantly posting messages to chat.
@michaelklishin further developed the concept and created some bots that opened hundreds of idle websockets connections to the server. They weren’t sending messages, but they triggered the creation of their own queues on the server which added more workload to RabbitMQ. All these scripts now have their own Github repository.
Besides from all the obscenity that you can get when you leave the internet without moderation, some funny messages passed around, like:
whats rabbitmq anyway, some weird language bindings to zmq?
It took more than 350 users and 2000+ messages/second to exhaust my the little VPS memory to crash the server. This can be prevented of course, as we will discuss later. In this case there was no flow control… no throttle, no nothing… just the internet free to take down a poor web chat baby. So what happened?
Hardening your Crash Proof Bunny
On detail that we have to keep into account when running RabbitMQ is that it is actually running on top of the Erlang Virtual Machine. This means that the issues that can make Erlang crash, can also crash RabbitMQ, or for that matter any system that you develop with Erlang.
In this particular case, after I took a look at the Erlang crash dump, I could find that the server somehow ran out of memory. What the Erlang Virtual Machine does when it runs out of memory is to exit the process. As simple as that.
A particular setting for RabbitMQ that can help in this case is the memory_high_watermark parameter that you can specify in your RabbitMQ configuration file. @michaelklishin suggested me to change it. The server was using 400MB top, that is about a 40% of the available memory that Erlang can detect from the machine. I changed that value to 80% so the new settings allowed the server to go up to 800MB if needed.
As I said before, the chat server didn’t implemented any kind of throttling. So as long as the websockets connection could get opened, then a new AMPQ Channel and a new Queue would be declared for that user. For the purposes of a proof of concept project or a prototype like this web chat it might be OK to run a system like in this way but if you do some serious production deployment of a RabbitMQ system, you will look at ways of preventing the server from getting flowed by connections, messages and hyper active producers.
There is much more you can do here to optimize your RabbitMQ server, like configure the number of Erlang Processes the server can spawn for example. You can see the description of the arguments accepted by the erl command here and the RabbitMQ configuration details here.
Running Smoothly
From that point it kept running pretty smoothly and I went to sleep when there were 530~ users online. How did I knew that… pretty simple. I used a simple shell command to count the number of private queues on the broker:
while true; do ./rabbitmqctl list_queues | grep amq. | wc -l; uptime; sleep 5s; doneIt uses the rabbitmqctl script to list the queues, it greps the queues whose name starts with amq. and pipes that to the wc command to get the number of lines. As simple as it can get. Poor man stats.
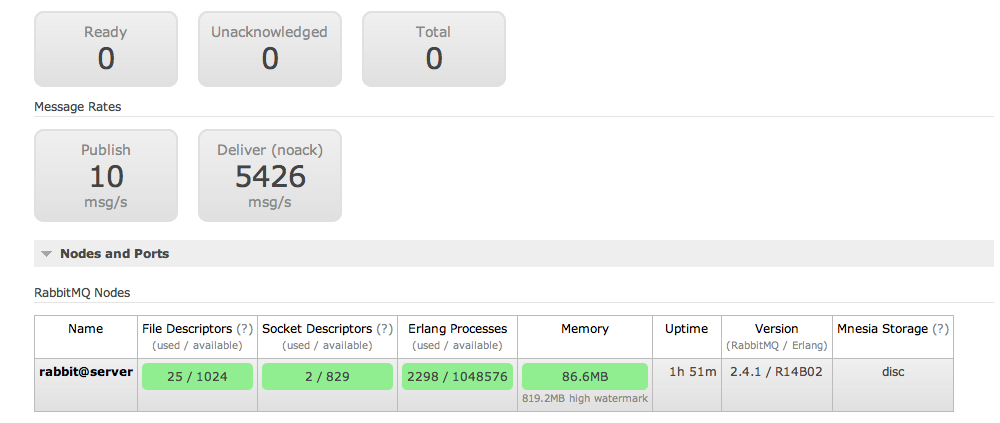
As you can see there, the server was routing more than 5000 messages per second using 86MB of RAM.
As the time passed I started to get tired since it was around 4:00AM, Sunday morning. I took some screenshots of the current broker status, made a small screen cast out of what was happening and went to bed. This is the video showcasing the server load average, number of routed messages, channels opened to the broker and queues.
The load average was pretty low. The same can be said of the memory used by the broker. It seems I was really cheating by using Erlang :D
After a day I took a look at google analytics, the response from Reddit was quite impressive:
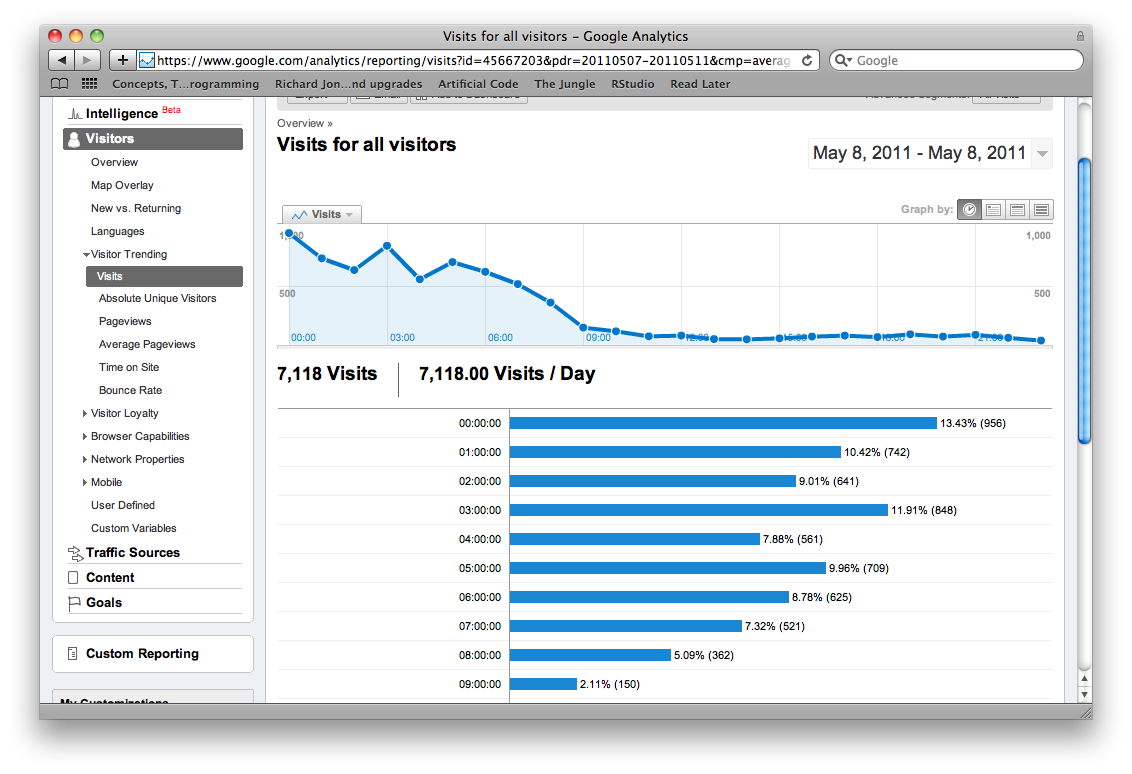
The chat got more than 7000 visits in one day. You can see that nearly a thousand of visits happened between 0:00 and 1:00 AM.
On Monday I decided to take the chat offline since the test was finished and people started to abuse the Gravatars, impersonating other persons. The chat didn’t have any kind of authentication, it didn’t store any messages nor user information. So it was not possible to check that the people using Gravatar was legitimate.
What I’ve learned
Apart that I’ve used RabbitMQ in production before, this scenario showed again that is a pretty robust software. Used with the default settings it crashed only because the memory allocated to it was reduced. It’s worth noting here that is the Erlang Virtual Machine what crashed when it runs out of memory.
Another point is that Erlang has some serious tools to keep a system alive. Apart from all the cool OTP behaviors like supervisors and gen_servers, you get for free tools like:
- Standard report logger
- Report browser, with filters by date, regex. etc. That makes it simple to browse through logs.
- Etop. Is like the unix
topcommand but for Erlang Virtual Machines.
Also it has things like and embedded database: Mnesia. Having a database that understand the language you are building your applications with simplifies the process a lot.
Then, thanks to the Erlang Distribution System, is pretty easy to hook into a running Erlang Virtual Machine and send messages to the running processes there. It’s also possible to perform RPC invocations. That simplifies the process of restarting some parts of the application while keeping others alive.
Finally a big thanks to the reddit/programming folks for joining the destroy the chat party last Saturday.